Google SSO
We've added Google as a Single Sign-On (SSO) provider. You can now log into Coalesce using Google Cloud or Google Workspace credentials Learn how to set up in Google SSO.
Updates
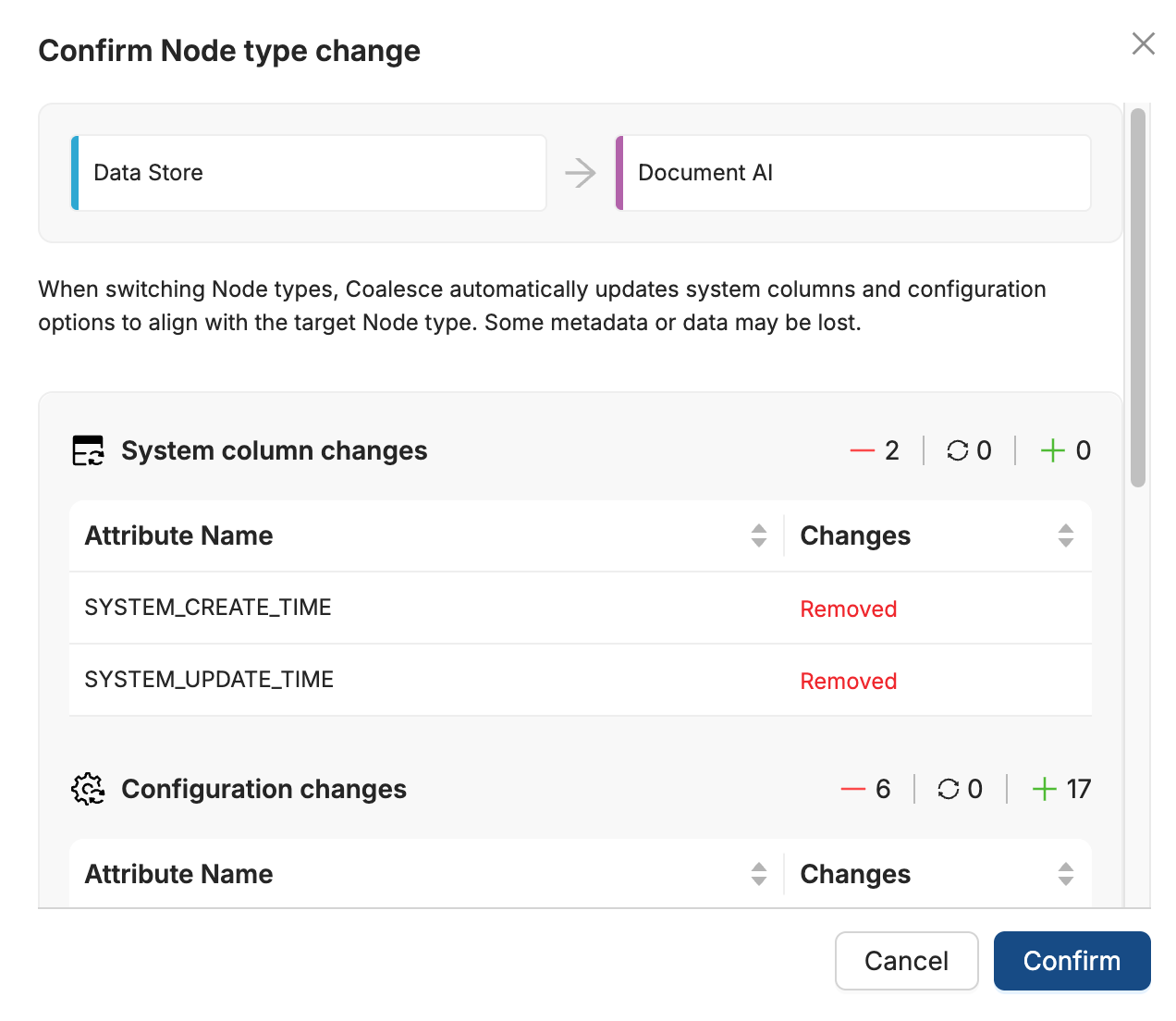
Copilot Create and Update V2 Nodes: When the SQL editor is enabled for your org, Copilot can now create and update V2 Node Types. Copilot writes V2 Nodes in raw SQL and automatically prevents mixing V1 and V2 Node Types.
Copilot Column Datatype and Nullability: Copilot can now change a column's datatype, precision, and nullability.
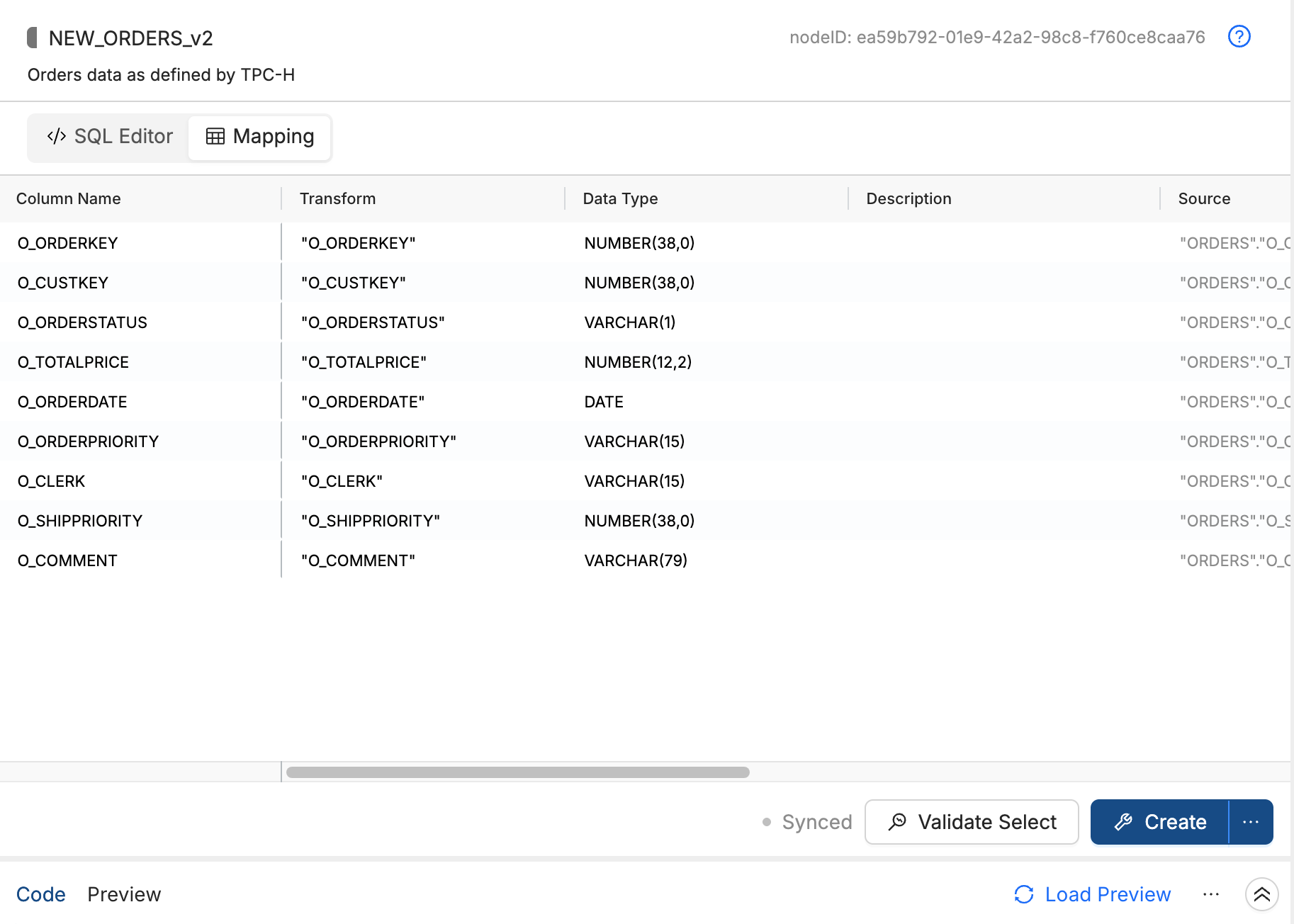
V2 Node Mapping Grid View: V2 Nodes now include a read-only mapping grid, accessible from the SQL editor. As you write SQL, the grid displays each column's transform, data type, source, nullability, description, and related fields.
Packages
Snowflake
Semantic View 1.0.1: Adds support for AI_SQL_GENERATION and AI_QUESTION_CATEGORIZATION on the Semantic View Node Type.
Dynamic Tables 2.1.8: Fixes Validate Select failures caused by the template rendering error 'ns' is undefined.
Base Node Types Advanced Deploy 2.5.5: Adds incremental loading and soft delete handling for Fact Advanced Deploy and Factless Fact Advanced Deploy Nodes.
Bug Fixes
Multi Source setNode Source Mapping: Fixed a bug where column sources and transforms were lost from all but the first source when using the setNode API on a Multi Source Node with a transformed column.
Force Checkout Data Loss Warning: Force checkout now correctly shows a data-loss warning when your version control repository format is stale, preventing accidental loss of uncommitted Workspace changes.
Azure DevOps Personal Access Token Expiration Error: When an Azure DevOps personal access token expires, you'll now see a clear error message with a direct link to the version control setup documentation.
AI Version Control Commit Message Size Limit: If a diff is too large for the AI commit message generator to process, you'll now see a specific error message instead of a generic 500 error.